Improving flag usage in code
Read time: 10 minutes
Last edited: Sep 18, 2024
Overview
This guide provides best practices and suggestions for improving code that uses feature flags. These practices can improve both code quality and ease of maintenance.
You can use code in tandem with your feature flags to maintain and improve the resilience of your process, including improving flag hygiene, giving your team more flexibility, refactoring flagged code to the degree that you need and no further, and generally increasing code quality.
Not all best practices work for everyone
The practices we offer in this guide are subjective. What may be a best practice for one team may not work as well for another. Review the recommendations in this guide and consider carefully if they will help your team before you implement them.
Concepts
In order to use this guide effectively, you should understand these concepts:
Improve flag hygiene
Most of the flags added to a project are temporary, intended to be removed later. Unfortunately, most teams are worse at removing flags than adding them, because removal is usually less urgent. This can lead to a codebase cluttered with flags that are no longer relevant. At best, this makes the code harder to read; at worst, inadvertently toggling the wrong flag can cause production failures.
Teams that use flags need to ensure that their code only references flags which are currently in use. This practice is known as “flag hygiene.” Here is a selection of techniques that help maintain good flag hygiene.
To learn more about flag hygiene, read Reducing technical debt from feature flags .
Extend your team’s “definition of done”
Engineering teams maintain their own standards for when a task or project can be considered “done.” For example, a team may consider the code for a task to be incomplete until it has automated tests.
You can maintain flag hygiene by ensuring that the temporary flags created for a task or project are no longer referenced by any code and are archived after they’re no longer in use. Adding this as a requirement to your team’s definition of done may help streamline your codebase, because only the flags you’re actively using will be present in it.
Code standards are easier to maintain with automated checks, such as those performed by a continuous integration (CI) system. You can even automate some flag hygiene checks.
Use code references to track flag hygiene
LaunchDarkly’s code references feature keeps track of the places in your code where each flag appears. It’s particularly useful when you need to clean up old flags.
Ensure that the code references for your project are up to date by integrating the ld-find-code-refs
tool with your code pipeline.
To learn more, read Code references .
Here is an image of the code references section for a feature flag:
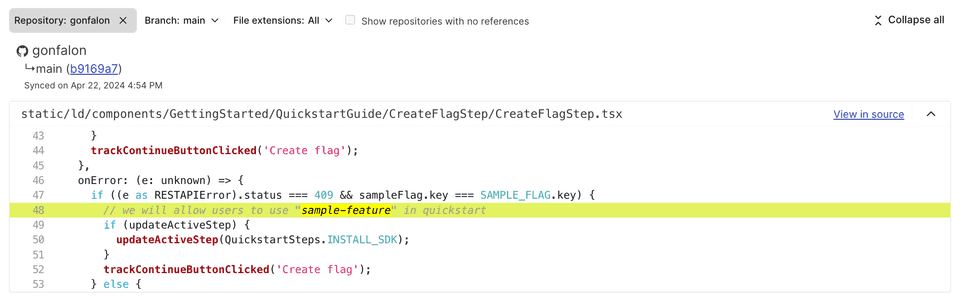
The code references section of a feature flag.
Refactor flagged code to reduce merge conflicts
Merge conflicts are a common source of friction when you make code changes. Adding flag logic in the middle of a function increases the chances that both that addition and its removal later will conflict with other changes.
To reduce the chance of conflicts, refactor both the flag logic and the code for each variation into their own functions. Keep the refactoring simple so that the overall time spent implementing the flag is short.
The examples below do not use a real coding language
The examples below use an approximation of a real coding language to illustrate the concepts they express. The language is based on JavaScript, but is not JavaScript.
Do not use these code samples in a production environment. They will not work.
Here’s an example to demonstrate this factoring tactic. The example code is taken from a fictional app which has a search feature which queries a back-end search engine. In the existing code, the function getSearchResults does the work of sending the search query to the backend, checking for errors and fetching the results.
Here is an example:
pseudocode
function getSearchResults(query, context) {
// 1. parse the query so engine can use it
// … query parsing logic goes here…
// 2. send the search query to the back-end search engine
engineURL = SEARCH_ENGINE_URL + ‘/search’;
response = sendRequest(engineURL, parsedQuery);
// 3. check for errors
if (response.body.starts_with(“SEARCH ERROR”)) {
// if there's an error, log the response and context details
log.ERROR("Search failure", response, context);
return new Error("There was an internal search error.");
} else {
// 4. turn response into a result list, clean up the results, etc.
// ... results logic goes here...
return results;
}
}
COPY
The app’s engineering team is preparing to migrate to a new, improved search engine. To prepare for the migration, the team has created the flag use-new-search-engine to tell the app which search back-end to use. The code needs to include code for querying both the old and the new search engines.
Inserting the flag logic in the middle of getSearchResults would make it even more complicated than it is already. Instead, they extract the relevant code and move it to new functions. They take the code which sends the query to the search engine (section 2 in the code above) and also code which processes errors and results (sections 3 and 4), because the new engine returns errors and results in a different format.
The team moves these lines of code, along with code for the new search engine and code to check the flag, into their own functions:
pseudocode
// This new version of the main function is much shorter,
// because it delegates the central work to executeSearch()
function getSearchResults(query, context) {
// 1. parse the query so engine can use it
// … query parsing logic goes here…
// 2. send the search query to the back-end search engine
response = executeSearch(parsedQuery, context);
return response;
}
// This function only checks the value of the “use-new-search-engine” flag
// and routes the query to one of the two functions below
// to do the actual querying and processing
function executeSearch(query, context) {
useNewEngine = ldclient.variation(“use-new-search-engine”, context, false);
if (useNewEngine == true) {
return queryNewEngine(query, context);
} else {
return queryOldEngine(query, context);
}
}
// This function queries the OLD search engine and processes the response
function queryOldEngine(query, context) {
engineURL = SEARCH_ENGINE_URL + ‘/search’;
response = sendRequest(engineURL, query);
if (response.body.starts_with(“SEARCH ERROR”)) {
log.ERROR("Search failure on old engine", response, context);
return new Error("There was an internal search error.");
} else {
// turn response into result list, clean up the results, etc.
// ... results logic goes here...
return results;
}
}
// This function queries the NEW search engine and processes the response
function queryNewEngine(query, context) {
engineURL = NEW_SEARCH_ENGINE_URL + ‘/query’;
response = sendRequest(engineURL, query);
if (response.type == “error”) {
log.ERROR("Search failure on new engine", response, context);
return new Error("There was an internal search error.");
} else {
// turn new-engine response into a result list
// ... results logic goes here...
return results;
}
}
COPY
The migration is expected to last a few weeks. Because the new feature is wrapped in a feature flag, the team can integrate the new search engine code before it’s been fully tested and optimized. Now, they can spend time improving the code with real production data. Because the new and old search engine code is separated into different functions, they can make those improvements without changing shared code. In addition, it’s easier to add unit tests for the new code because they can call it directly without needing to create mock flag states.
When it’s time to retire the old search engine and archive the feature flag, the cleanup is minimal and less likely to cause merge conflicts.
The cleanup steps are:
- Delete the
executeSearchandqueryOldEnginefunctions. - Rename
queryNewEnginetoexecuteSearch. - Within
queryNewEngine, change thelog.ERRORmessage from"Search failure on new engine"to just"Search failure", because there is only one engine now.
Avoid additional refactoring
Both queryOldEngine and queryNewEngine contain similar code. Another version of this example could even contain more lines of code which are duplicated between both functions. You might want to refactor further by moving the duplicated code into a shared function.
There are a couple of reasons not to deduplicate code.
- The code is not intended for long-term maintenance. After the migration is finished, the duplicates are deleted.
- There is likely to be short-term maintenance as you improve
queryNewEngine. Premature refactoring may hinder that maintenance more than it helps.
We recommend the common refactoring adage known as the rule of three : don’t refactor for deduplication until code is duplicated three or more times.
Improve code quality
Adding feature flags to code increases its flexibility, but can also add complexity. The more complex your code is, the more difficult it is to diagnose and correct an unexpected problem.
There are various techniques you can use to make sure that your feature flags help accomplish what you want to do with code.
Here are some guidelines you can follow to make sure you write high-quality code:
Avoid passing flag state in a call interface
When you use a feature flag to change the behavior of a component, perform the flag evaluation inside the component.
It can be tempting to add a dedicated parameter to the call interface and send the flag state from the outside. However, changing the component’s interface means that all the component’s callers have to be changed too, and then changed again once the flag is removed.
Consider the executeSearch function we used as an example earlier. It calls ldclient.variation to evaluate the flag from within its own implementation.
If we moved that call out to getSearchResults and sent the flag value to executeSearch as an argument, the abbreviated code would look like this:
pseudocode
function getSearchResults(query, context) {
// 1. parse the query so engine can use it
// … query parsing logic goes here…
// 2. send the search query to the back-end search engine
// with the feature flag value
useNewEngine = ldclient.variation(“use-new-search-engine”, context, false);
response = executeSearch(parsedQuery, context, useNewEngine);
return response;
}
// useNewEngine is now supplied in the call
function executeSearch(query, context, useNewEngine) {
if (useNewEngine == true) {
return queryNewEngine(query, context);
} else {
return queryOldEngine(query, context);
}
}
COPY
The purpose of our flag-oriented refactoring was to reduce merge conflicts by separating out the code that would need to change, and keeping it contained in dedicated functions. Unfortunately, putting the flag evaluation code in getSearchResults has given it more responsibility that it didn’t need, and removed the benefits of the refactoring.
In this example, the changed interface only had one caller. When changing functions and modules with many callers, there’s even greater benefit in keeping the interface the same. This is especially important given the other risks inherent in changing heavily-used code.
Flags can change any time
The more frequently that your code is executed, the more likely it is that your code will be in the middle of executing when a vital flag is changed. If your code is constructed in a way that expects flag state to stay consistent between the start and end of a code path, it can cause problems that are particularly hard to debug.
One way to avoid this problem is to use LaunchDarkly’s custom roles feature to restrict who can access the flag.
To learn more, read Custom roles .
This can make it harder to change a flag, which can be good in some cases, but it also increases the friction in your development process. Instead of making change more difficult, it’s better to improve the robustness of your code.
The following example uses a service that sends batches of data through a processing pipeline. Each batch must go through three processing steps: normalization, relabeling, and storage.
A dedicated service performs each of these steps. The storage step is always the last, but the normalization and relabeling can happen in either order. Each service is responsible for sending the data batch to the next service.
There are two possible orders in which the processing steps can be performed. The order is chosen using a feature flag called process-order which has variations normalize-first and relabel-first.
The normalize-first order is:
- Normalization
- Relabeling
- Storage
The relabel-first order looks like this:
- Relabeling
- Normalization
- Storage
Each service is responsible for sending its output to the next step.
It’s tempting to have each service evaluate the process-order flag after it’s processed and use this to decide the next step. However, if the flag is flipped in the middle of processing, this could cause problems.
If the flag is set to normalize-first, the batch starts at the normalization service. Before that service finishes processing, someone flips the flag to enable the relabel-first process. When the normalization service finishes processing, it’ll evaluate the process-order flag and use the relabel-first ordering, in which the normalization step is followed by storage. This data batch should be sent to the relabeling service because it hasn’t been relabeled, but it will be sent to storage instead.
This is an example of a situation in which flag consistency is required throughout multiple steps. The flag should be evaluated once for each batch, and that value should be sent in the call from service to service.
Conclusion
In this guide, we covered:
- Using code references to find feature flags in your codebase
- When and how to refactor to streamline your code
- How to improve code quality with flags
提高代码中特性标志使用的最佳实践
阅读时间:10分钟
最后编辑:2024年9月18日
概览
本指南提供了最佳实践和建议,以改善使用特性标志的代码。这些实践可以提高代码质量和维护的便利性。
您可以将代码与特性标志一起使用,以维护和提高您流程的弹性,包括改善标志卫生、为团队提供更多灵活性、在需要的程度上重构标志代码,以及普遍提高代码质量。
并非所有最佳实践都适用于每个人
本指南中提供的做法是主观的。对于一个团队来说可能是最佳实践,对于另一个团队可能效果不佳。在实施之前,请仔细考虑这些建议是否能帮助您的团队。
概念
为了有效地使用本指南,您应该理解以下概念:
提高标志卫生
项目中添加的大多数标志都是临时的,打算稍后移除。不幸的是,大多数团队在移除标志方面比添加标志更差,因为移除通常不那么紧迫。这可能导致代码库中充满了不再相关的标志。这在最好的情况下会使代码更难阅读;在最坏的情况下,不小心切换错误的标记可能会导致生产失败。
使用标志的团队需要确保他们的代码只引用当前正在使用的标志。这种实践被称为“标志卫生”。以下是一些有助于维护良好标志卫生的技术。
要了解更多关于标志卫生的信息,请阅读减少特性标志的技术债务 。
扩展团队的“完成定义”
工程团队维护自己的标准,以确定何时可以认为任务或项目“完成”。例如,一个团队可能认为,除非代码有自动化测试,否则任务的代码不完整。
您可以通过确保为任务或项目创建的临时标志不再被任何代码引用,并且在不再使用后被归档,来维护标志卫生。将此作为团队完成定义的要求,可能有助于简化您的代码库,因为只有您正在积极使用的标记才会出现在其中。
通过持续集成(CI)系统执行的自动化检查,更容易维护代码标准。您甚至可以自动化一些标志卫生检查。
使用代码引用跟踪标志卫生
LaunchDarkly的代码引用 功能跟踪您的代码中每个标志出现的位置。当您需要清理旧标志时,它特别有用。
通过将 工具集成到您的代码管道中,确保您的项目的代码引用是最新的。
要了解更多信息,请阅读代码引用 。
这里是功能标志的代码引用部分的图片:
功能标志的代码引用部分。
重构标志代码以减少合并冲突
合并冲突是进行代码更改时常见的摩擦源。在函数中间添加标志逻辑会增加该添加及其后续删除与其他更改冲突的可能性。
为了减少冲突的机会,重构标志逻辑和每个变体的代码到它们自己的函数中。保持重构简单,以便实现标志的总时间很短。
下面的示例不使用真正的编程语言
下面的示例使用近似于真实编程语言的示例来说明它们表达的概念。该语言基于JavaScript,但不是JavaScript。
不要将这些代码示例用于生产环境。它们将无法工作。
以下是一个演示这种分解策略的示例。示例代码来自一个虚构的应用程序,该应用程序具有查询后端搜索引擎的搜索功能。在现有代码中,函数getSearchResults负责将搜索查询发送到后端、检查错误并获取结果。
以下是一个示例:
伪代码
function getSearchResults(query, context) {
// 1. 解析查询以便引擎可以使用
// ...查询解析逻辑在这里...
// 2. 将搜索查询发送到后端搜索引擎
engineURL = SEARCH_ENGINE_URL + '/search';
response = sendRequest(engineURL, parsedQuery);
// 3. 检查错误
if (response.body.starts_with("SEARCH ERROR")) {
// 如果有错误,记录响应和上下文详细信息
log.ERROR("Search failure", response, context);
return new Error("There was an internal search error.");
} else {
// 4. 将响应转换为结果列表,清理结果等
// ...结果逻辑在这里...
return results;
}
}
应用程序的工程团队正准备迁移到一个新的、改进的搜索引擎。为了准备迁移,团队创建了标志use-new-search-engine来告诉应用程序使用哪个搜索后端。代码需要包括查询旧搜索引擎和新搜索引擎的代码。
在getSearchResults中间插入标志逻辑会使它比已经复杂的情况更加复杂。相反,他们提取相关代码并将其移动到新函数中。他们将发送查询到搜索引擎的代码(上述代码中的第2部分)以及处理错误和结果的代码(第3和第4部分),因为新引擎以不同的格式返回错误和结果。
团队将这些代码行,以及新搜索引擎的代码和检查标志的代码,移动到它们自己的函数中:
伪代码
// 这个主函数的新版本更短,
// 因为它将中心工作委托给executeSearch()
function getSearchResults(query, context) {
// 1. 解析查询以便引擎可以使用
// ...查询解析逻辑在这里...
// 2. 将搜索查询发送到后端搜索引擎
response = executeSearch(parsedQuery, context);
return response;
}
// 这个函数只检查“use-new-search-engine”标志的值
// 并将查询路由到下面的两个函数之一
// 执行实际的查询和处理
function executeSearch(query, context) {
useNewEngine = ldclient.variation("use-new-search-engine", context, false);
if (useNewEngine == true) {
return queryNewEngine(query, context);
} else {
return queryOldEngine(query, context);
}
}
// 这个函数查询旧搜索引擎并处理响应
function queryOldEngine(query, context) {
engineURL = SEARCH_ENGINE_URL + '/search';
response = sendRequest(engineURL, query);
if (response.body.starts_with("SEARCH ERROR")) {
log.ERROR("Search failure on old engine", response, context);
return new Error("There was an internal search error.");
} else {
// 将响应转换为结果列表,清理结果等
// ...结果逻辑在这里...
return results;
}
}
// 这个函数查询新搜索引擎并处理响应
function queryNewEngine(query, context) {
engineURL = NEW_SEARCH_ENGINE_URL + '/query';
response = sendRequest(engineURL, query);
if (response.type == "error") {
log.ERROR("Search failure on new engine", response, context);
return new Error("There was an internal search error.");
} else {
// 将新引擎响应转换为结果列表
// ...结果逻辑在这里...
return results;
}
}
预计迁移将持续几周。由于新特性被包装在特性标志中,团队可以在新搜索引擎代码完全测试和优化之前集成它。现在,他们可以花时间使用真实生产数据改进代码。由于新旧搜索引擎代码被分离到不同的函数中,他们可以在不更改共享代码的情况下进行这些改进。此外,由于可以直接调用新代码而无需创建模拟标志状态,因此更容易为新代码添加单元测试。
当需要退役旧搜索引擎并归档特性标志时,清理工作最少,不太可能引起合并冲突。
清理步骤如下:
- 删除
executeSearch和queryOldEngine函数。 - 将
queryNewEngine重命名为executeSearch。 - 在
queryNewEngine中,将log.ERROR消息从"Search failure on new engine"更改为仅"Search failure",因为现在只有一个引擎了。
避免额外的重构
queryOldEngine 和 queryNewEngine 都包含类似的代码。这个示例的另一个版本甚至可能包含更多在两个函数之间重复的代码行。您可能想要通过将重复的代码移动到一个共享函数中来进一步重构。
有几个原因不进行代码去重。
- 代码并非为长期维护而设计。迁移完成后,重复的代码将被删除。
- 在您改进
queryNewEngine时,可能会有短期的维护工作。过早的重构可能会比帮助更多地阻碍维护。
我们推荐一个常见的重构格言,称为《三的法则》 :在代码重复三次或更多次之前,不要为了去重而进行重构。
提高代码质量
在代码中添加特性标志增加了其灵活性,但也可能增加复杂性。代码越复杂,诊断和纠正意外问题就越困难。
您可以使用各种技术来确保特性标志帮助您实现代码的目标。
以下是一些您可以遵循的指导方针,以确保您编写高质量的代码:
避免在调用接口中传递标志状态
当您使用特性标志来改变组件的行为时,请在组件内部执行标志评估。
可能很想在调用接口中添加一个专用参数,并从外部发送标志状态。然而,改变组件的接口意味着所有调用该组件的代码也必须改变,一旦标志被移除,又需要再次改变。
考虑我们之前用作示例的 executeSearch 函数。它调用 ldclient.variation 在其自己的实现内部评估标志。
如果我们将那个调用移到 getSearchResults 并将标志值作为参数传递给 executeSearch,简化后的代码将如下所示:
伪代码
function getSearchResults(query, context) {
// 1. 解析查询以便引擎可以使用
// ...查询解析逻辑在这里...
// 2. 将搜索查询发送到后端搜索引擎
// 带有特性标志值
useNewEngine = ldclient.variation("use-new-search-engine", context, false);
response = executeSearch(parsedQuery, context, useNewEngine);
return response;
}
// `useNewEngine` 现在在调用中提供
function executeSearch(query, context, useNewEngine) {
if (useNewEngine == true) {
return queryNewEngine(query, context);
} else {
return queryOldEngine(query, context);
}
}
我们以标志为导向的重构目的是为了通过分离出需要改变的代码,并将其包含在专用函数中,来减少合并冲突。不幸的是,在 getSearchResults 中放入标志评估代码,给它带来了它不需要的更多责任,并消除了重构的好处。
在这个例子中,改变的接口只有一个调用者。当改变有多个调用者的函数和模块时,保持接口不变的好处更大。鉴于改变频繁使用的代码的其他风险,这一点尤其重要。
标志可以随时改变
您的代码执行得越频繁,当一个关键标志被改变时,您的代码在执行中途的可能性就越大。如果您的代码构建方式期望标志状态在代码路径的开始和结束之间保持一致,它可能会导致特别难以调试的问题。
避免这个问题的一种方法是使用 LaunchDarkly 的自定义角色功能来限制谁可以访问该标志。
要了解更多信息,请阅读自定义角色 。
这可能会使改变标志变得更加困难,在某些情况下可能是好事,但它也增加了您开发过程中的摩擦。与其使改变更加困难,不如提高代码的健壮性。
以下示例使用一个服务,该服务将批量数据通过处理管道发送。每个批次必须经过三个处理步骤:规范化、重新标记和存储。
一个专用服务执行这些步骤中的每一个。存储步骤始终是最后一个,但规范化和重新标记可以以任何顺序发生。每个服务负责将数据批次发送到下一个服务。
有两种可能的顺序可以执行处理步骤。顺序是使用一个名为 process-order 的特性标志选择的,该标志有 normalize-first 和 relabel-first 两种变化。
normalize-first 顺序是:
- 规范化
- 重新标记
- 存储
relabel-first 顺序如下:
- 重新标记
- 规范化
- 存储
每个服务负责将其输出发送到下一步。
在每个服务处理后评估 process-order 标志并使用此来决定下一步是很诱人的。然而,如果在处理中途标志被翻转,这可能会导致问题。
如果标志被设置为 normalize-first,则批次从规范化服务开始。在该服务完成处理之前,有人翻转了标志以启用 relabel-first 过程。当规范化服务完成处理时,它将评估 process-order 标志并使用 relabel-first 顺序,在该顺序中,规范化步骤后跟存储。这个数据批次应该被发送到重新标记服务,因为它还没有被重新标记,但它将被发送到存储服务。
这是一个需要在整个多个步骤中保持标志一致性的情况示例。标志应该为每个批次评估一次,并且该值应该在服务之间的调用中发送。
结论
在本指南中,我们涵盖了:
- 使用代码引用在您的代码库中找到特性标志
- 何时以及如何重构以简化您的代码
- 如何通过标志提高代码质量